안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임’ 중 ‘Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://www.youtube.com/watch?v=IUwfhbZYTno)

해당 논문은 현재 Pretrain Language 모델이 준수한 성능을 보이고 있고, 다양한 학습 방식으로 대부분의 task에서 활용될 수 있다고 언급합니다. 예를 들어 BERT는 마스크 인 필링이나 Prediction을 통해서 Self Supervised learning을 하고, BART 역시 노이즈를 디노이징하는 방식으로 많은 Pretrain Language 모델이 발전해왔습니다.
하지만 task specific 한 구조를 갖는 모델을 위하여 성능이 그런 task들을 비해서 다소 낮고 Pretraining을 진행하는 동안 시간과 비용이 많이 소모됨을 이야기합니다. 또한 모델의 knowledge가 parameterize 되어 있다 이야기하는데, 이는 특정 Input이 모델로 들어가고 output이 어떤 부분에 모델의 어떤 파라미터를 참고하고 산출되는지 알기가 어렵습니다.
이런 PLM단점을 보완하기 위해서 Retrieval 한 방법이 있다고 설명합니다. Retrieval 모델은 이름과 같이 knowledge base에서 검색 Retrieval를 진행하고 해당 Input에 맞는 context를 찾아서 던져주는 모델을 의미합니다.
예시로 real m과 같은 모델은 준수한 성능을 보이고 있습니다. 다만 이런 모델은 학습 시 label이 필요하다는 단점이 있습니다.
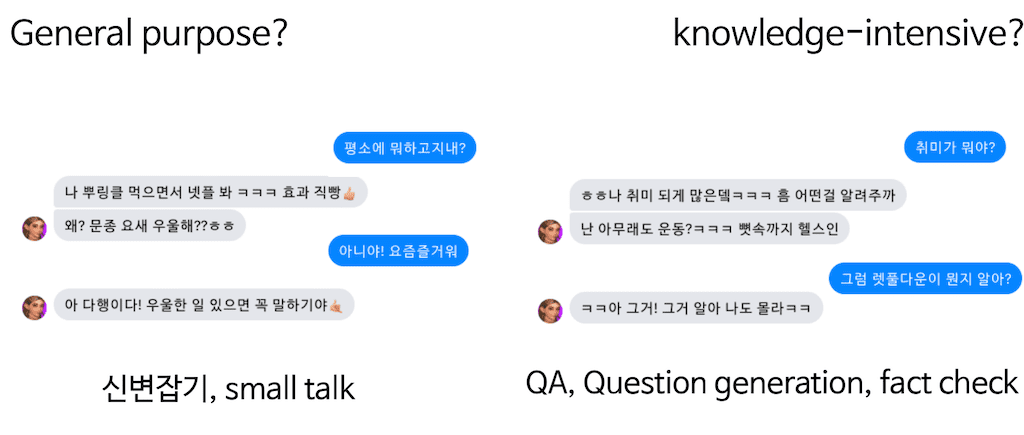
일단 General purpose와 knowledge-intensive task의 차이점입니다. 위의 대화는 하슬아라는 virtural 인플루언서와의 대화입니다. 좌측에 대화는 신변잡기, small talk으로 하슬아하고 나눈 기록입니다. 23살 여성이라는 페르소나를 가지고 있습니다. 그래서 virtual 휴먼으로 적절한 답변을 하고 있는 것을 볼 수 있습니다.
하지만 우측을 보시면 취미가 헬스라고 해갖고 랫 풀다운이라는 운동에 대해서 물어봤는데 뼛속까지 헬스인이라는 맥락을 잡고 이야기를 진행해보았는데 virtual 휴먼과 일종의 QA을 진행했습니다. 그런데 답변이 조금 이상해지는 거를 알 수 있습니다.
물론 하슬아의 페르소나가 전문가나 교수가 아니기 때문에 해당 대화가 적절한 비유가 되기는 좀 힘들겠으나 하슬아를 단순히 PLM으로 생각한다면 Knowledge-Intensive기반 QA, 그리고 Question generation 그리고 fact check 같은 부분에서 성능이 좋지 못하다는 것을 알 수 있습니다.
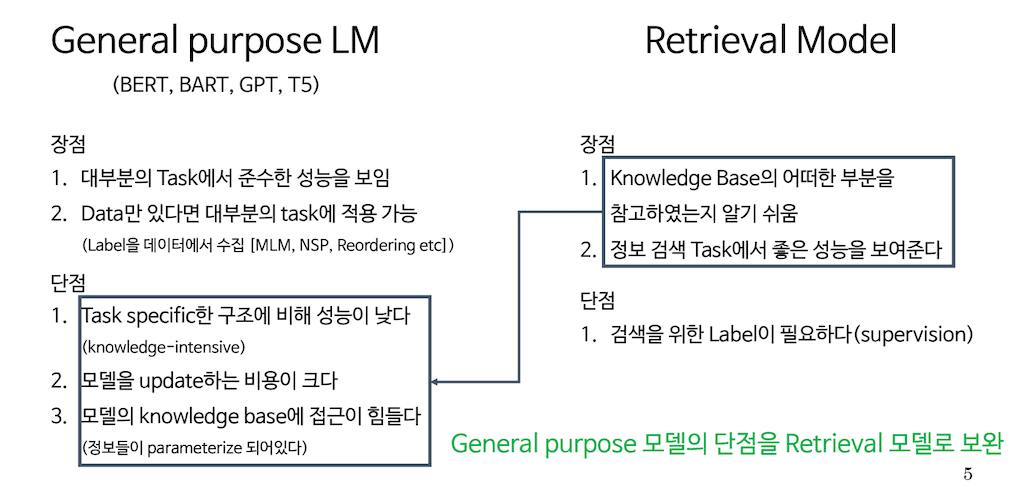
때문에 이런 PLM의 단점을 knowledge base와 이를 참고할 능력이 있는 Retrieval를 붙여줌으로써 PLM의 성능을 Knowledge-Intensive 한 task에서도 조금 더 끌어올리겠다는 Motivation을 해당 논문에서 갖고 있습니다.

다시 말해서, 하슬아에게 사전을 선물한다면 즉, 지식이 parameterize 되어 있는 모델의 non parametric 한 Knowledge base가 있고, 이를 검색할 수 있는 Retrieval를 붙여준다면 Knowledge-Intensive 기반 task를 조금 더 잘 수행할 수 있지 않을까 하는 부분에서 이 논문의 내용은 시작됩니다.
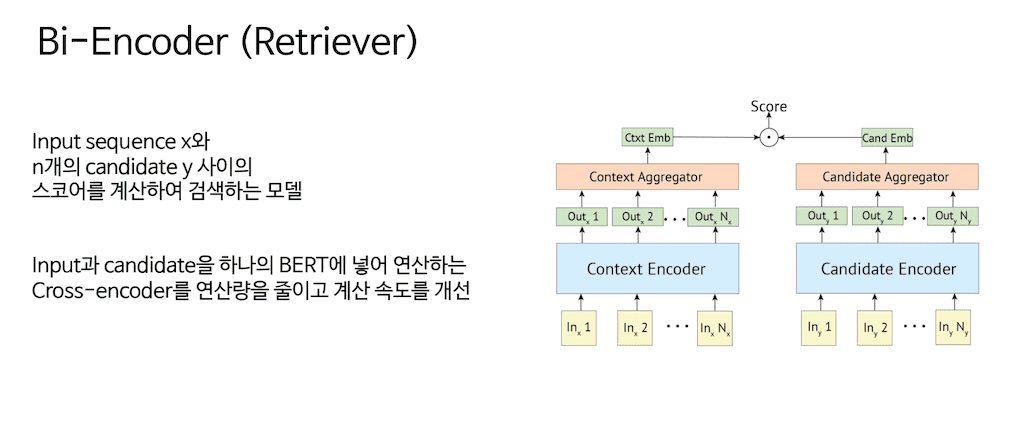
Background에서 Bi-Encoder입니다.
Bi-Encoder는 해당 논문에서 Retrieval 역할을 하게 됩니다. Bi-Encoder는 특정 Input이 있고 여러 개의 candidate이 존재할 때 Input에 맞는 적절한 candidate을 찾아내는 모델이라고 생각해 주시면 됩니다. 해당 모델은 총 두 개 encoder가 필요한데, 두 개 encoder는 BERT로 이루어져 있습니다. 그리고 독립적인 BERT로 이루어져 있습니다. 그래서 query encoder BERT입니다. 그리고 candidate encoder 역시 BERT입니다.
이것을 따로 두고 query와 그에 맞는 candidate을 병렬적으로 계산할 수 있기 때문에 이전에 제시되었던 cross encoder에서는 하나의 BERT에 Input과 separation 토큰이 들어가고 그다음 candidate이 들어가는 하나의 long Sequence로 들어가게 되는데 이렇게 되면은 시간 복잡도가 n제곱으로 되기 때문에 굉장히 느린 단점을 보완하기 위해서 Bi-Encoder라는 Retrieval가 고안되었습니다. 이는 굉장히 빠르게 작동한다는 장점이 있습니다.
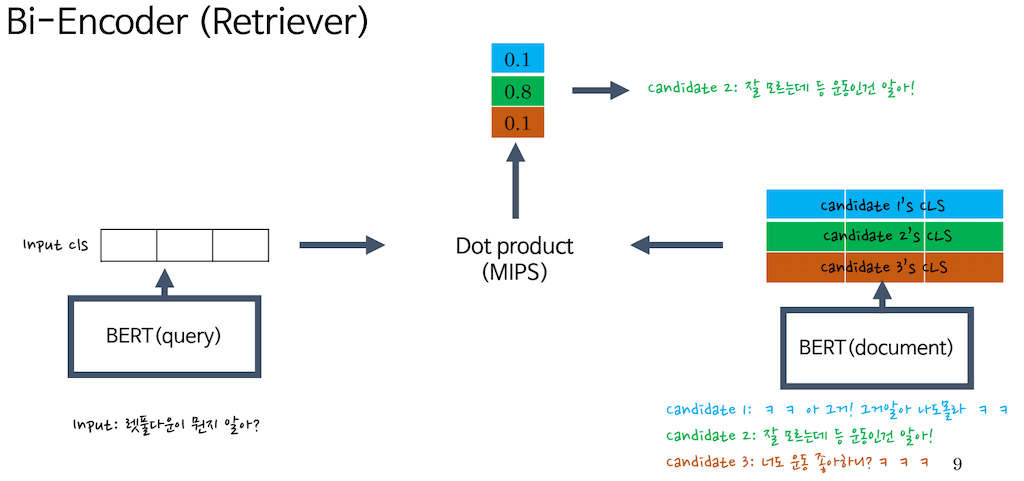
더 구체적으로 설명을 드리면 Bi-Encoder에서는 이 두 개의 BERT가 있습니다. BERT(query) 그리고 BERT(document)라고 명명하겠습니다. 둘 다 sentence embedder로 생각해주시면 편할 것 같습니다. 먼저 Input을 BERT(query)에 주입하고 해당 CLS 토큰을 뽑아냅니다. 이를 Input representation으로 간주하고 그리고 여러 개의 candidate을 BERT(document)에 순차적으로 넣어서 문장별 Cls를 뽑아냅니다.
candidate1는 나도 몰라 라는 렛 풀다운을 물어봤을 때 하슬아가 뱉었던 답변입니다. 두 번째, 세 번째는 Bi-encoder를 설명하기 위해서 임의로 만든 답변입니다.
candidate 2는 잘 모르는데 등 운동인 건 알아!로 CLS라고 가정하겠습니다.
candidate3은 너도 운동 좋아하니?
그리고 이것을 Dot product attention을 진행합니다. 그리고 해당 Dot product attention을 진행하게 되면은 해당 candidate에 맞는 score가 나오게 되고, 두 번째 응답이 가장 적절하다고 생각을 해서 이 두 번째 응답을 뽑아냈습니다.
아까 말씀드렸다시피 Bi encoder 즉, Retrieveal 모델을 학습시키기 위해서는 적절한 응답을 label로 갖고 있어야 됩니다. 따라서 candidate 2가 label로 설정되어 있을 겁니다.
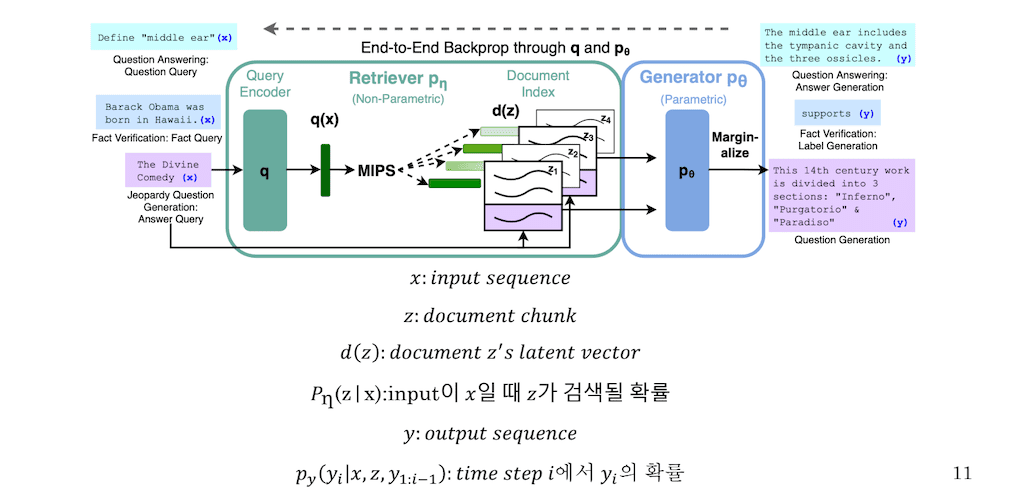
다음은 method입니다. 먼저 definition을 한번 짚고 넘어가겠습니다.
x는 Input Sequence입니다. 그리고 query encoder를 통해서 나온 representation을 q(x)라고 명명합니다. z는 document chunk라고 위키피디아를 100 단어씩 끊어 놓은 한 문장이라고 생각하시면 됩니다. d(z)는 document z의 representation을 뽑아낸 겁니다. representation는 document BERT를 통해서 embedding 등 하나의 vector로 매트릭스로 이루어졌다라고 생각하시면 됩니다. 그리고 pn(z|x)는 Input이 x일 때 z가 검색될 확률입니다. 즉, query vector와 그리고 이 매트릭스와 Dot product attention을 진행하면 그에 대한 score라고 이해하시면 될 것 같습니다.
그리고 y은 Output Sequence. 타겟이 됩니다. 그리고 Py(yi|x,z,y1:i-1)까지 토큰이 주어지고 이는 time step i에서의 yi의 확률이라고 이해하시면 될 것 같습니다.
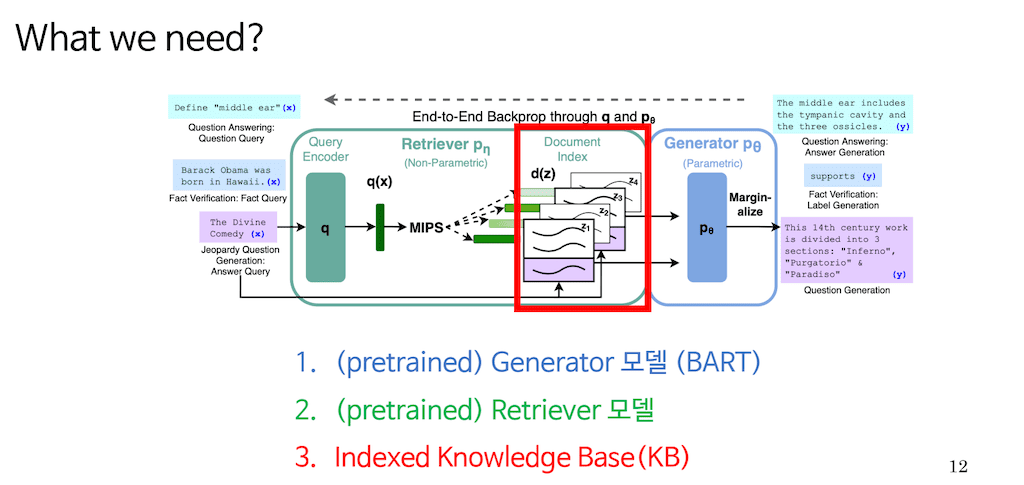
앞서 말씀드린 구조를 만들기 위해서는 총 세 가지 준비물이 필요합니다.
먼저 Generator 모델. BART T5와 같은 Sequence to Sequence 모델이나 아니면 gpt 같은 Generator여도 상관없습니다. 해당 논문에서는 BART를 이용하여 학습을 진행하였습니다.
두 번째는 Retriever입니다. 본 논문에서는 Bi-encoder를 사용하였습니다. 다만 아까 백그라운드에서 보여드린 BERT document는 학습을 시작하기 전에 미리 knowledge base들을 embedding 한 다음에 더 이상 사용되지 않습니다. 이유에 대해서는 다음 슬라이드에서 언급하겠습니다
세 번째는 위키피디아 트위터 같은 knowledge base입니다.
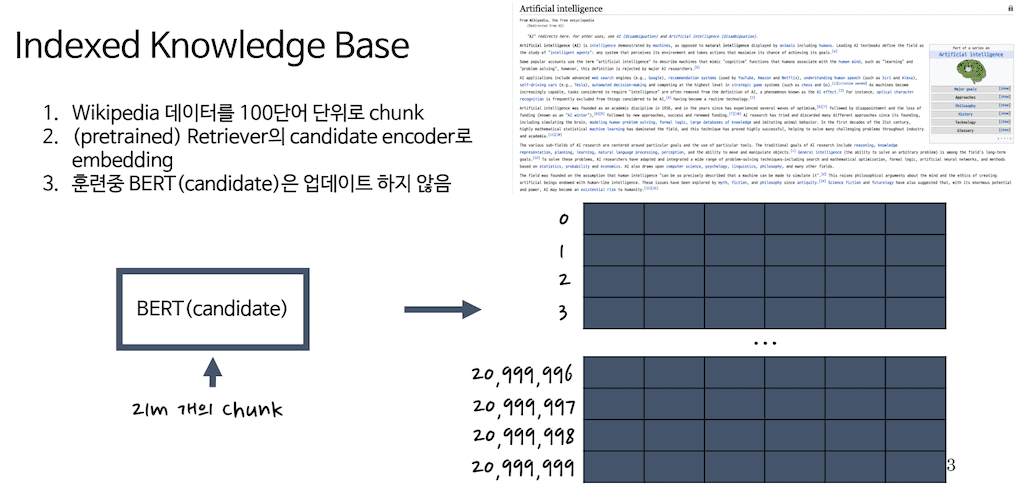
knowledge base에 대해서 한번 더 짚고 넘어가겠습니다. 논문에서는 특히 Indexed Knowledge base라고 언급하였습니다. Indexed Knowledge base는 사실 위키피디아를 100단어 단위로 자른 뒤 해당 chunk를 candidate embedder에 넣어 추출한 representation의 집합입니다. 오른쪽 그림에 매트릭스 형태로 존재합니다.
논문에서는 2018년도 위키 chunk를 사용하였는데 100 단어 단위로 자른 chunk가 총 2100만 개가 있었다고 합니다.
앞에 페이지에서 candidate BERT는 이런 chunk representation을 뽑은 뒤 사용되지 않는다고 말씀드렸는데 만약 이 BERT를 업데이트하게 된다면 2100만 개의 representation 역시 업데이트되어야 합니다. 때문에 비용과 시간이 굉장히 많이 소요됩니다. 또한 업데이트하지 않더라도 성능에 직접적인 영향은 없다고 논문에서 언급합니다.
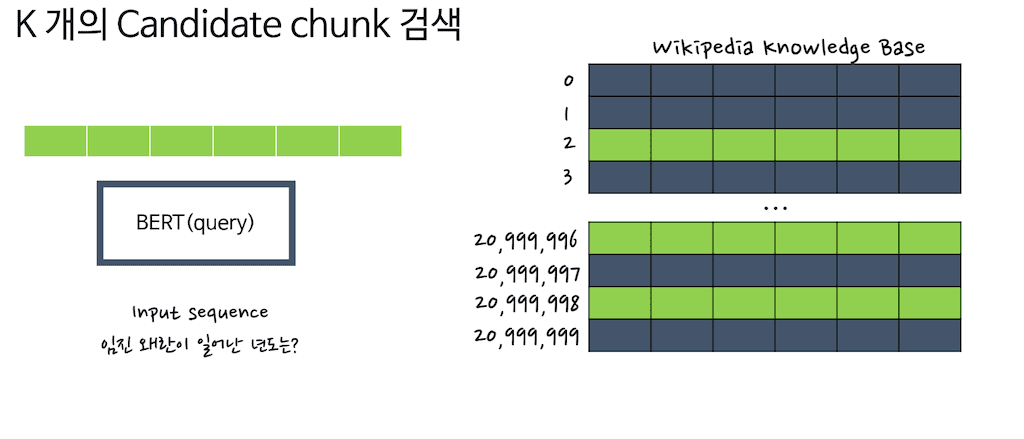
먼저 Retrieval를 하는 과정을 살펴보겠습니다. Input을 query encoder에 넣은 뒤, document encoder로 미리 embedding 해놓은 knowledge base와 Dot product를 진행하게 됩니다. 그래서 top k개의 index score가 high score를 뽑아냅니다. 여기서 top K를 3으로 설정하겠습니다. 만약에 세 개의 index가 높은 score를 가지고 있으면 이 세 가지 index를 뽑아냅니다. 그 후에 decoding을 거치게 됩니다.

해당 논문에서는 총 Decoding strategy를 두 가지로 이야기합니다. 하나는 PRAG-Token decoding 방법. 하나는 PRAG-sequence decoding 방법입니다.
PRAG-Token decoding 방법은 굉장히 스탠다드한 방식의 beam searching으로 이해하시면 될 것 같습니다.
다음은 PRAG-sequence decoding Strategy가 있는데 이거는 time step마다 k개의 chunk를 beam searching 한다고 적어 놓았는데, 사실 time step마다 k개의 chunk를 beam searching 하는 게 아니라, whole Sequence y를 뽑아놓고 document 간의 beam Search를 진행하고 싶은데 토큰 별로 document를 searching 해서 확률 distribution이 나온 게 아니라서 document별로 beam searching을 하기는 굉장히 힘듭니다.
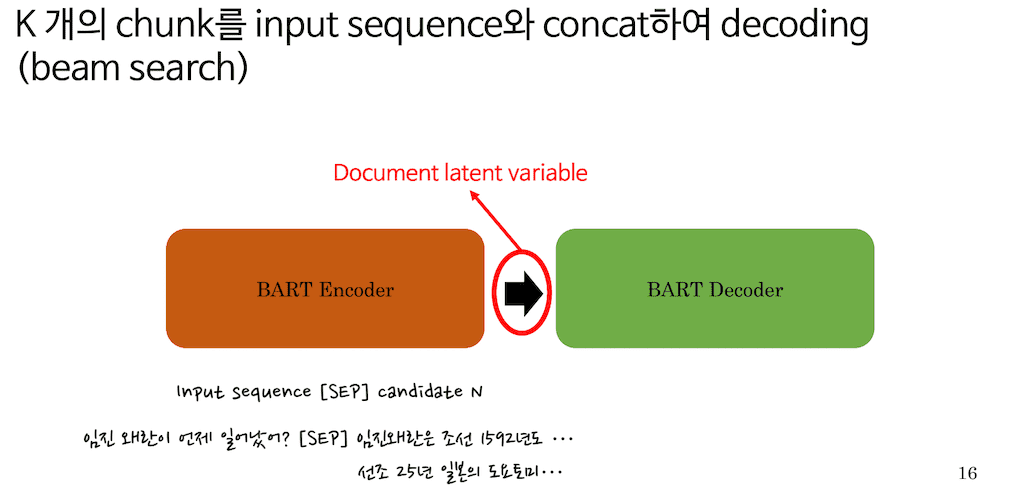
먼저 PRAG-Token 방식의 decoding입니다. 아까 세 개를 말씀드렸는데 이렇게 3가지 문장이 있다고 생각해주시면 편할 것 같습니다. 아까 서칭 한 세 가지의 index를 단순히 Input Sequence와 SEP 토큰 하나 거치고, Input을 임진왜란이 언제 일어났어라고 물어봤을 때, 임진왜란은 조선 1592년도… 이러한 Sequence가 해당 index에 들어있었다고 가정을 해보겠습니다. 단순히 SEP 토큰을 거치고 Sequence를 Concat 한 다음에 하나의 long Sequence로 BART encoder에 넣습니다. BART encoder에 총 세 가지 버전의 knowledge base가 encoding 되고 이를 document latent variable이라고 논문에서는 이야기합니다.
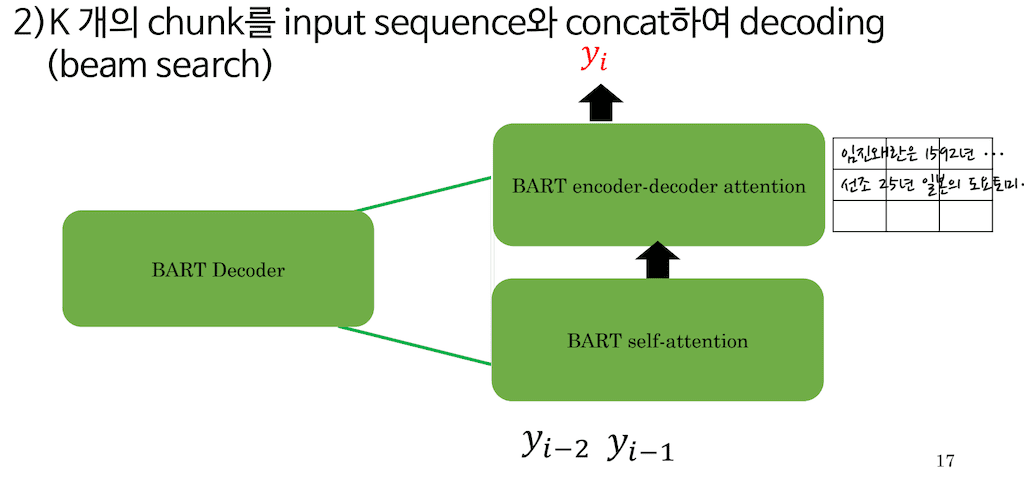
BART decoder에서는 해당 time step yi를 뽑아내기 위해 총 세 가지, knowledge index에 대한 attention을 진행하고 아까 document latent variable 이라고 명명한 것이 보시는 것 같이 하나의 vector로 이루어져 있다고 생각해주시면 좋을 것 같습니다.
때문에 PRAG-Token 방식의 decoding은 매 토큰이 generation 될 때마다 뽑힌 top k개의 document를 따로따로 attention 하는 장점이 있습니다. 그래서 토큰 별로 각각 다른 document를 참고할 수 있습니다.
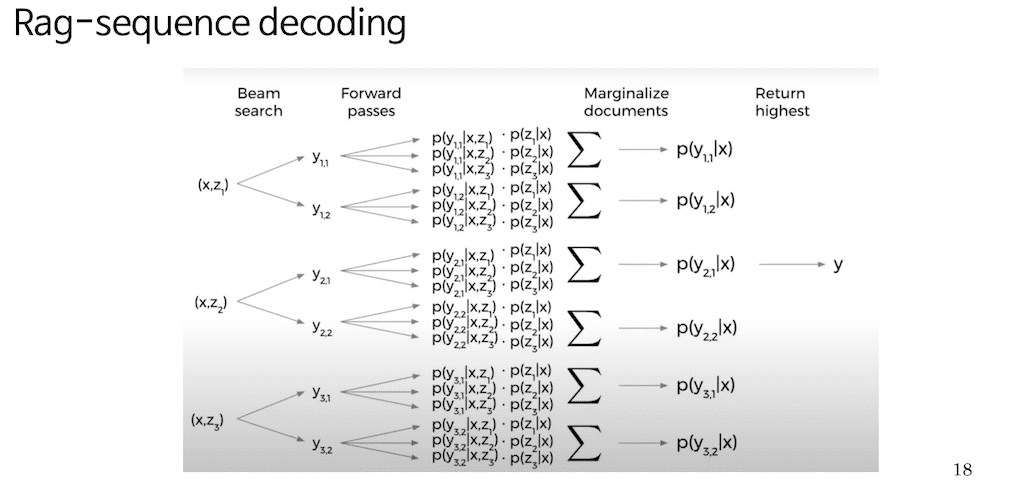
PRAG-Sequence decoding입니다. 그림은 논문 1 저자가 자신의 논문 리뷰하는 영상을 유튜브에서 가져온 예시입니다. X 가 있을 때 총 세 가지의 top K개의 document를 찾았다고 가정을 해보겠습니다. 그래서 하나의 홀 Sequence를 뽑아내는데 총 두 가지 후보가 beam Search로 찾아졌다고 가정을 해보겠습니다. 아까 document에 대한 Beam Search를 진행하고자 하였다고 이야기를 했는데 사실 여기에서 (x, z1) (x, z2), (x, z3)가 나오는 걸 알 수 있습니다.
PRAG-sequence 방식에서는 knowledge base를 뽑아낸 다음에 토큰 별로 다시 knowledge base를 다시 검색하는 것이 아니라 Retrieval는 총 decoding에서 한 번만 진행되고 그래서 갖고 있는 확률을 가지고 beam Search를 진행해야 되기 때문에 단순히 x가 주어졌을 때 다른 문서가 검색될 확률을 곱해주고 거기서 최고 확률을 가진 Sequence를 내보내는 방식입니다. 그래서 PRAG-sequence 방식은 whole Sequence가 Generation 될 때, 총하나의 document만 참고한다는 특징이 있습니다.

다음은 실험 부분입니다. 실험에서 해당 모델의 setup에서 generator는 BART-Large 그리고 pretrained에 대한 언급은 없습니다. BART- Large를 사용하였고 위키피디아 2018년 dump를 사용하였습니다.
아까 말씀드린 바와 같이 100개 단어로 chunk를 하였고, CPU에 담아서 FAISS를 이용해서 MIPS를 진행하였다고 합니다. 총 100GB의 메모리가 들었다고 합니다.
그리고 아까 말씀드린 것처럼 Retrieval에서 총 k를 3으로 예시 들었는데 해당 논문에서는 K를 5 또는 10으로 해서 문서를 검색하였다고 이야기합니다.

knowledge Intensive task는 해당 논문에서는 총 4가지로 진행을 하였습니다.
첫 번째는 Open Domain QA. 문장으로 이루어진 질의가 있고, 해당 Open Domain QA는 1개에서 5개로 이루어진 답안을 가지고 있습니다. 그니까 1~5개 단어이면 답안이 굉장히 짧습니다.
마찬가지로 Open Domain QA지만 Abstractive opendomain QA는 문장으로 이루어진 질의가 있고, 하나의 완전한 문장으로 이루어진 답변이라는 특징을 가지고 있습니다. 그리고 또 MS MARCO라는 데이터셋을 사용하는데, 질의가 있으면 10개 Gold passage가 주어지고 특정 Gold passage에서 답을 생성하는, 힌트가 주어지는 Open domain QA이라고 생각해주시면 편할 것 같습니다.
세 번째는 Fact Verification입니다. Language에서 어떤 문장이 주어지고 그 문장이 팩트인지 아닌지, 아니면 정보가 부족한지 판단하는 것은 FEVER-3입니다. 그리고 정보가 맞는지 아닌지만 판단한 것은 FEVER-2라는 데이터셋입니다. 그래서 총 Claim과 Evidence가 주어지고, Evidence가 claim을 서포트하면은 맞다는 이야기고 아니면 틀린 이야기가 됩니다.
네 번째는 Quesition Generation입니다. Answer가 주어지고 그에 해당하는 질의를 생성합니다. 예를 들어서 Answer가 The World Cup이라고 하면은 1986년 멕시코는 해당 대회를 개최한 첫 번째 나라가 되었다고 하는 질문을 생성하는 겁니다. 해당 데이터셋은 지금까지 Question Generation이라는 데이터셋을 사용하였습니다.
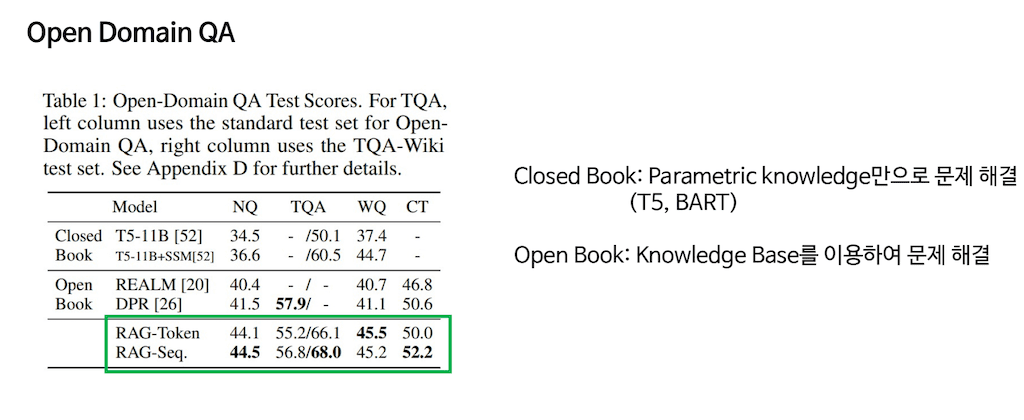
먼저 Open Domain QA부터 살펴보겠습니다. 해당 score를 보시면은 PRAG-Token과 PRAG-sequence가 SOTA를 많이 달성하는 것을 확인할 수 있습니다. 특이한 점을 살펴보면 TQA는 Closed Book으로 Closed Book은 Parametric Knowledge만으로 문제를 해결하였다 라는 이야기입니다. 그래서 Input이 들어가고, 그 Input에 맞는 답안을 T5 가 그 자체로 생성하였다고 합니다.
Open Book은 Retrieval모델로 생각해 주시면 됩니다. Open Book은 해당 knowledge base가 있고, Input에 따른 knowledge base에서 적절한 knowledge base를 검색하여서 해당 task를 수행하는 방법입니다.
PRAG 모델은 두 가지 방식을 전부 다 수행할 수 있는데, knowledge Retrieval를 뺀다면 Parametric 한 방법이고, knowledge Retrieval를 붙인다면 non Parametric한 방법도 사용하겠다라고 이야기할 수 있습니다. 그래서 상당히 많은 부분에서 SOTA를 달성하였다는 것에서 Open Domain QA는 좀 의미가 있었다고 합니다.

두 번째로 Abstractive Open Domain QA입니다. SOTA는 Palm이라는 모델입니다. *은 Gold passage를 사용해서 문제를 해결한 것입니다. Bing log에서 추출한 질문이고 그에 대한 response가 Gold passage로 주어진다고 합니다.
저자가 얘기하기로는 Bing log에서 추출한 질문이기 때문에, Gold Passage를 사용하지 않고 달성하였다는 것에서 좀 의미가 있다고 설명합니다.
예를 들어서 어제 날씨 어땠어라고 하면은 무조건 Gold Passage가 있어야 해당 답안을 생성을 할 수 있는데 PRAG-Token과 PRAG-sequence 모델은 Gold Passage를 사용하지 않고 해당 score를 달성합니다. BART보다 이 점에서 많게는 3점까지 점수 차이가 납니다.

세 번째는 Fact verification입니다. 마찬가지로 Palm이라는 모델입니다. 그리고 *는 Gold evidence를 사용해서 문제를 해결하였습니다. SOTA는 Input에 claim을 넣고, evidence가 claim을 서포트하냐라는 방식으로 output label을 이용하여서 학습을 하였습니다.
RAG과 BART는 Input은 claim만 output은 label만을 이용하여 claim을 집어넣으면 이것이 참이다, 아니다, 알 수 없다 이 세 가지로 분류하여 학습을 하였습니다.
마찬가지로 evidence가 주어지지 않은 상황에서 knowledge base만을 이용하여서 해당 score를 달성한 것은 의미 있는 성과다라고 이야기를 합니다. 그리고 BART를 크게 우회하는 성능을 보여주기도 합니다.
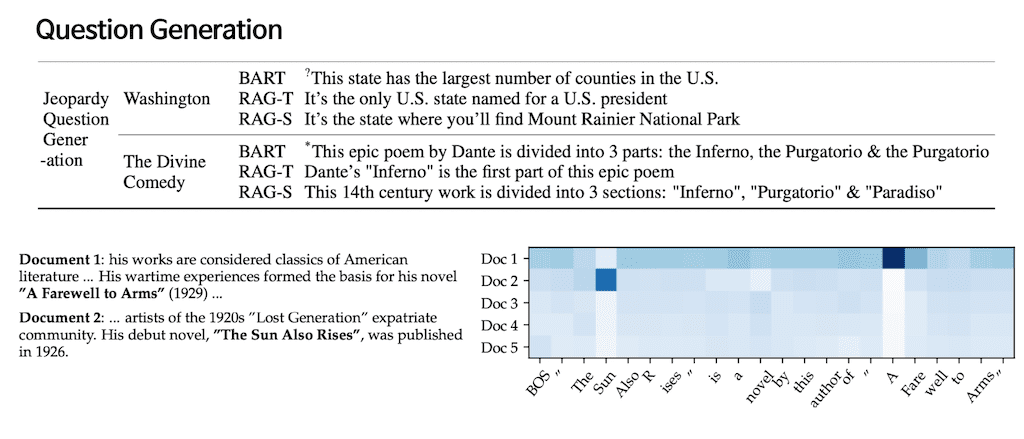
Question Generation입니다. 아까 PRAG-Token Generation 방식은 토큰 별로 각각 다른 문서를 참고할 수 있다는 장점이 있었는데 여기서 BOS 토큰이 주어지고 The, Sun까지 주어진 걸 보면 Doc2에서 attention score가 좀 높게 나타난 것을 이해할 수 있습니다. 그리고 Doc2를 읽어보면 “The Sun Also R ises” is라는 어떻게 보면 굉장히 유사한 의미가 있는 knowledge base에서 의미 있는 context를 뽑아냈다고 이야기할 수 있습니다. 그래서 실험 결과는 Retrieval에 대한 label이 없더라도 충분히 의미 있는 context를 뽑아낼 수 있었다는 것에서 의미가 있습니다.
? 는 부분적으로 좀 틀린 말, *는 완전히 틀린 말입니다. 하지만 PRAG-Token과 PRAG-sequence를 보면 굉장히 자연스럽고 잘 맞는 질문을 생성하는 것을 확인할 수 있습니다.
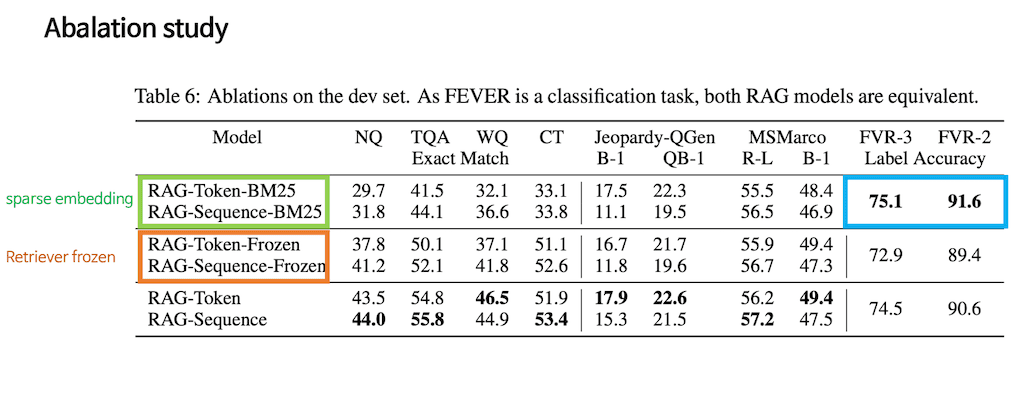
Ablation study입니다. Ablation study는 PRAG Token과 PRAG-sequence 방식을 전부 가져왔습니다. 그리고 차이점을 보자면 아까는 Dense 한 방식의 Retrievaer를 사용하였다면 BM-25 방식은 해당 Sequence를 sparse 한 embedding 방식을 했다고 생각해 주시면 될 것 같습니다.
그래서 확실히 Open Domain QA나 아니면 Question Generation 같은 부분에서는 Dense한 방식이 훨씬 더 괜찮다, 준수한 score를 보여준다 라는 것을 볼 수 있습니다.
FVR 같은 경우는 sparse한 방식이 조금 더 높은 성과를 보여주는데, 이는 label과 Input이 일치하는 단어가 많기 때문에 sparse한 방식의 embedding이 조금 더 나은 성과를 보여준다고 설명합니다.
주황색으로 표시한 부분은 Retrieval를 FineTuning하지 않고 Frozen 시킨 다음에 BART에 있는 parameter 만 업데이트를 시켜줬습니다. 그래서 사실 Retrieval의 성능이 좋아지지 않고 BART만 업데이트시켰을 때 성능이 굉장히 하락하는 것을 볼 수 있습니다.
그래서 Retrieval 그리고 knowledge base의 엄청난 Defendency를 갖고 있다 라는 것을 알 수 있습니다.

기존 setup은 2018년 wiki dump를 사용합니다. 그런데 knowledge base만 2016년 wiki dump로 바꾼 다음에 2016년에서 2018년에 지도자가 바뀐 데이터셋이 있는데 who is the {position}?이라고 하면 World leader 중에서 바뀐 사람을 알 수 있습니다. 예를 들어서 who is the president of Republic of Korea라고 하면은 2016년 knowledge base를 갖고 있다면 박근혜라고 이야기를 할 거고, 2018년 knowledge base를 갖고 있다면 문재인이라고 이야기를 합니다.
해당 실험 결과를 보면 2016년 knowledge base를 갖고 있을 때 2016년 리더를 응답한 비율이 70%고 2016년 knowledge base로 2018년 리더를 응답한 비율이 4%입니다. 2018년 knowledge base를 가지고 있을 때 2018년 리더를 응답한 비율이 68%입니다. 그래서 knowledge base에 굉장히 모델이 dependent 한다 라는 것을 보여줍니다.
RAG 모델은 knowledge base에 따라서 응답을 산출해내고 모델 전체를 재학습 시키지 않고 knowledge base만 바꿔주는 것만으로도 어느 정도 튜닝 효과가 있습니다.

결론입니다. 해당 논문은 General purpose 한 모델을 Retrieval과 결합하여서 knowledge Intensive 한 task에 대한 E2E 레시피를 제공하였고, 특정 task에서 Gold Passage 그리고 evidence 사용 없이 갖고 있는 knowledge base만을 이용하여서 의미 있는 score를 기록하였습니다. 그리고 knowledge base hot-swapping. 아까 말씀드린 2016년 knowledge base를 2018년으로 바꿔 주는 것만으로 해도 모델을 어느 정도 다시 튜닝한 효과를 볼 수 있었습니다.